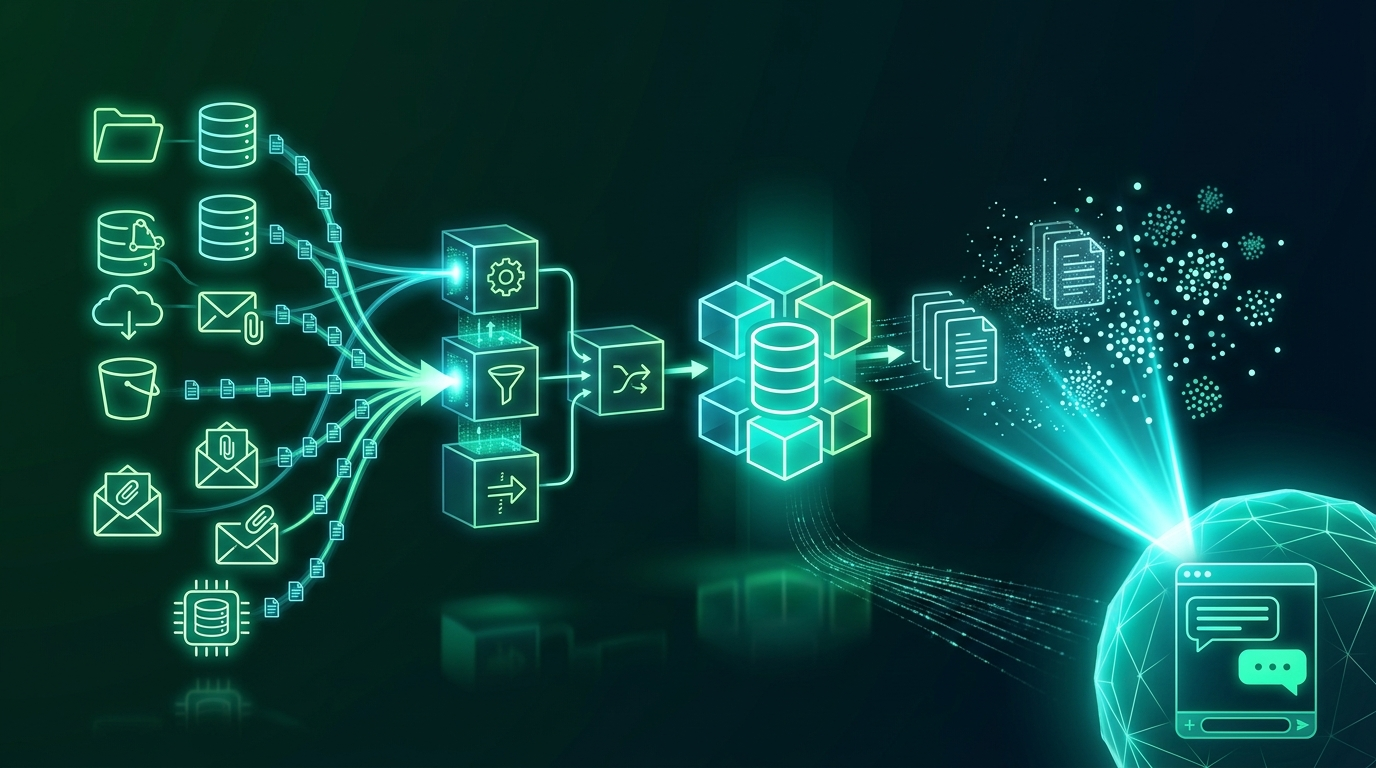
The Solution: An Automated Multi-Source Data Pipeline with Production RAG
Spundan designed and deployed a production-grade data ingestion pipeline and RAG architecture that continuously pulls, processes, embeds, and retrieves knowledge across all enterprise sources. Key strategic components included:
- Multi-Source Data Connectors: Built automated connectors for SharePoint, S3, Confluence, SQL databases, and email archives — continuously ingesting new and updated documents without manual intervention.
- Intelligent Document Processing: Deployed a multi-format parsing pipeline handling PDFs, DOCX, XLSX, HTML, and scanned images (via OCR) with layout-aware extraction that preserves tables, headers, and section structure.
- Smart Chunking Strategy: Implemented semantic and hierarchical chunking — splitting documents by meaning rather than fixed token counts — to preserve context across chunk boundaries and improve retrieval accuracy.
- Embedding & Vector Store: Generated dense embeddings using domain-tuned embedding models and indexed them into a Qdrant vector store, enabling fast, accurate semantic similarity search across millions of document chunks.
- Hybrid Retrieval: Combined dense vector search with BM25 keyword search in a hybrid retrieval layer, ensuring both semantic relevance and exact-term matching for regulatory and technical queries.
- RAG Orchestration & Citation: Built a LangChain-based RAG orchestration layer that retrieves the top-k most relevant chunks, constructs grounded prompts, and returns answers with source citations — enabling full auditability of every AI response.
- Continuous Pipeline Monitoring: Implemented pipeline health dashboards tracking ingestion lag, embedding freshness, retrieval relevance scores, and answer quality metrics to ensure the knowledge base stays current and accurate.